{kind=link}
{kind=link}
紫花苜蓿 PGIP同源基因克隆与序列核苷酸多态性分析
[桂枝1  , 肖婷
, 肖婷1, 2 , 皮永硕1 , 袁庆华3 , 杨建翔1 , 刘妍1 , 高建明1 ]
, 肖婷, 皮永硕]
|
|


第一作者:桂枝(1973-),女,山西太原人,副教授,硕士,主要从事饲用作物遗传育种的研究。E-mail:guizhi73@163.com;肖婷(1993-),女,湖南邵阳人,在读硕士生,主要从事水稻栽培的研究。E-mail:1755044399@qq.com
多聚半乳糖醛酸酶抑制蛋白(PGIP)是植物重要的防卫蛋白之一,了解 PGIP基因的核苷酸序列是对其进行分子遗传学与分子生物学研究的前提与基础。本研究采用同源克隆法,从16个紫花苜蓿( Medicago sativa)品种的集群DNA中克隆了7个苜蓿 PGIP基因的部分基因组编码序列,分别对应于蒺藜苜蓿( M. truncatula)7个不同的 PGIP基因,并命名为 MsPGIP5、 MsPGIP6、 MsPGIP7、 MsPGIP8、 MsPGIP9、 MsPGIP10和 MsPGIP11。其中, MsPGIP5、 MsPGIP6、 MsPGIP8、 MsPGIP9和 MsPGIP11的单核苷酸多态性(Single Nucleotide Polymorphism,SNP)位点间的平均距离分别为20、74、34、423和21 bp,差异较大。对 MsPGIP5、 MsPGIP6、 MsPGIP8和 MsPGIP11进行荧光标记PCR单链构象多态性(FPCR-SSCP)分析,结果表明,其等位基因数目与PCR片段长度的比值分别为20、56、22和19 bp,变化趋势与这4个基因SNP位点间的平均距离基本一致。比较而言,在发现的7个苜蓿 PGIP基因中, MsPGIP9序列高度保守, MsPGIP5和 MsPGIP11的变异较大,而 MsPGIP6与 MsPGIP8的变异中等。
Polygalacturonase-inhibiting proteins(PGIP)are one of the most important defensive proteins, and the understanding of the nucleotide sequences of PGIP genes is the premise and basis of the molecular genetics and molecular biology. This study aimed to isolate the genomic coding sequences of PGIP genes in alfalfa( Medicago sativa)by a homology-based method. Consequently, the part genomic coding sequences of 7 PGIP genes were cloned, and each of these 7 alfalfa PGIP genes had a corresponding homologous PGIP gene from M. truncatula, and they were named as MsPGIP5, MsPGIP6, MsPGIP7, MsPGIP8, MsPGIP9, MsPGIP10 and MsPGIP11. Of the found 7 alfalfa PGIP genes, MsPGIP5, MsPGIP6, MsPGIP8, MsPGIP9 and MsPGIP11 possessed a divergent average inter-SNP distance with a value of 20, 74, 34, 423 and 21 bp, respectively. FPCR-SSCP analysis was performed for MsPGIP5, MsPGIP6, MsPGIP8 and MsPGIP11, and the results showed that a trend of the ratios between their SSCP allele numbers and their PCR fragment sizes, with a value of 20, 56, 22 and 19 bp, respectively, and they were basically consistent with those of their average inter-SNP distances. In contrast, of the found 7 alfalfa PGIP genes, the sequence of MsPGIP9 was highly conserved while MsPGIP5 and MsPGIP11 displayed a large sequence variation, and MsPGIP6 and MsPGIP8 had a median sequence variation.
多聚半乳糖醛酸酶抑制蛋白(Polygalacturonase-inhibiting Protein, PGIP)是植物重要的防卫蛋白之一, 能专一性地抑制病原真菌或其他病原物分泌的内切多聚半乳糖醛酸酶(Endo-polygalacturonase, endo-PG)的活性, 从而阻止病原物的侵入和扩展, 同时促进植物体内寡聚半乳糖醛酸的积累, 激活特定的防卫反应, 最终抑制相应病害的发生[1, 2, 3, 4, 5]。PGIP是一类具有不同外形的细胞外糖蛋白, 属于富含亮氨酸重复(Leucine-rich Repeat, LRR)的蛋白质超家族, 含有包括20~30个氨基酸的共有重复序列(LxxLxLxxNxLxGxIPxxLxxLxxL), 重复次数一般为10, 形成β -折叠/β -转角/β -折叠/α -螺旋结构, 即LRR基序[2]。所有已知的PGIP有相似的一级结构, 除了LRR基序外, 还包括两个与之相邻的富含半胱氨酸残基的高度保守区域, 一个在C端, 一个在N端, 以形成二硫键来稳定PGIP分子[5]。LRR基序则是蛋白质间相互作用的区域, PGIP通过LRR基序中暴露于外表面的氨基酸残基与PG活性位点处的氨基酸残基相互作用, 从而抑制PG的活性[6]。PGIP分子中还有一段长24~29个氨基酸的信号肽, 参与PGIP分子从内质网向细胞间的转运[7]。
获得DNA序列并研究其特点是对基因进行分子遗传学与分子生物学研究的前提与基础。目前, 有关PGIP的研究大多涉及基因克隆、表达调节及转基因等方面[8, 9, 10], 对其遗传变异的研究却甚少[11], 在苜蓿属植物中, 有关PGIP的研究报导仅有两项。Song和Nam[12]在豆科模式植物— — 蒺藜苜蓿(Medicago truncatula)中克隆了两个PGIP基因(MtPGIP1和MtPGIP2)序列, 并研究了其在几个非生物因素和两种致病真菌胁迫下根、茎、叶中的表达变化。Degra等[13]则从四倍体苜蓿的根瘤中分离出一个PGIP蛋白。在已经完成的模式植物蒺藜苜蓿的基因组测序结果中共发现了19个PGIP基因(M. truncatula sequence databank:http://www.jcvi.org/cgi-bin/medicago/overview.cgi), 其中13个含有9~10个LRR保守基序, 其余6个仅含有5个LRR保守基序。天津农学院“ 苜蓿PGIP基因的遗传变异研究” 课题组已经分离了4个含有9~10个LRR保守基序的苜蓿(M. sativa)PGIP基因(MsPGIP1、MsPGIP2、 MsPGIP3和MsPGIP4, 其GeneBank编号分别为JF338622、JF338623、JF338624和JF338625), 他们在蒺藜苜蓿的19个PGIP基因中均有对应的同源基因。本研究采用同源克隆法, 分离对应于蒺藜苜蓿的19个PGIP基因中余下的9个含有9~10个LRR保守基序的苜蓿PGIP基因的基因组序列, 并采用测序和荧光标记PCR单链构象多态性(Fluorescence-based PCR single-strand conformation polymorphism, FPCR-SSCP)的方法对其序列核苷酸多态性进行初步分析, 以期为进一步开展这些基因与苜蓿对重要病害的抗性间的关联分析和这些基因的分子生物学研究提供基础。
选用16个具有广泛地理分布的苜蓿品种为材料, 进行PGIP基因的基因组序列的克隆和核苷酸多态性的研究(表1)。每个品种随机选取20株(共320株), 取幼叶进行基因组DNA的提取, 提取方法采用Doyle和Doyle[14]的CTAB法, 并稍加改动, 最后以λ DNA 作为参照标准, 用0.8%琼脂糖凝胶对DNA的质量和数量进行电泳检测。每株取等量DNA混合, 组成集群DNA, 用于PGIP基因的基因组序列的分离。另取64株(每品种4株)进行FPCR-SSCP分析。
| 表1 本研究所用苜蓿品种 Table 1 16 alfalfa genotypes tested in the study |
将9个含有10个LRR保守基序的蒺藜苜蓿PGIP基因的氨基酸序列对齐后, 进行系统发育分析, 结果分为4类。将每类的保守序列与拟南芥(Arabidopsis thaliana)、菜豆(Phaseolus vulgaris)等植物的PGIP保守序列进行对比后, 设计多对简并引物, 经PCR优化后, 每类选择一对带型清晰、预期产物长度与实际产物长度接近的简并引物用于分离苜蓿PGIP基因的基因组序列(表2)。PCR反应体系:总体积20 μ L, 30 ng集群DNA模板, 1.0 μ mol· L-1正向引物与反向引物(Shanghai Sangon, China), 1.0 U Taq DNA聚合酶(Takara, Japan), 0.2 mmol· L-1 dNTPs, 1.5 mmol· L-1 MgCl2。PCR程序:95 ℃ 5 min; 94 ℃变性30或45 s, 50~55 ℃退火60 s, 72 ℃变性60或90 s, 共进行35个循环; 72 ℃延伸10 min。其中, 4对引物的退火温度分别为55、50、54和50 ℃, 引物对MSPF31/MSPR31的变性和延伸时间分别为30和60 s, 其余3对引物对均为45和90 s。PCR产物检测采用加有溴化乙锭(EB)的1.5%的琼脂糖凝胶电泳进行。将扩增良好的目的条带切下, 加入TE(pH 8.0)20 μ L, 充分捣碎。纯化后, DNA片段被连接入pBS-T载体中, 转化大肠杆菌DH5α .3, 带有目的片段的转化子送北京三博远志生物技术有限责任公司进行单向或双向测序。每个目的片段测序50~100个转化子。
| 表2 本研究设计的简并引物 Table 2 Degenerate primers designed in the study |
对测序后发现的每个PGIP基因, 经多序列对齐后, 设计2~3对特异引物, 以使其扩增片段包含较多的核苷酸变异。然后进行PCR与SSCP电泳优化, 选择重复性最好的一对引物用于最后的分析。FPCR-SSCP分析中的荧光标记、PCR反应体系、反应程序及电泳方法等基本同Gui等[15]的方法, 但退火温度因引物不同而不同, 且电泳缓冲液改为0.6× TBE, 电流则改为5.5 mA。电泳后, 使用TRlO+Typhoon扫描仪(Amersham Biosciences, USA)扫描图像。采用人工方法判定等位基因。
蒺藜苜蓿相关PGIP基因的序列数据从其测序数据库(M. truncatula sequence databank:http://www.jcvi.org/cgi-bin/medicago/overview.cgi)中下载。序列编辑采用BioEdit 7.2.5[16]进行, 多序列对齐使用MEGA5中的Muscle方法[17]进行, 并进行轻微的人工修饰。采用人工方法设计简并引物, 特异性引物的设计采用PerlPrimer 1.1.17[18]进行。对于所有测序的转化子, 先使用BioEdit 7.2.5在蒺藜苜蓿CDS和蛋白质数据库(Mt4.0v1_GenesCDSSeq_20130731_1800和Mt4.0v1_GenesProteinSeq_20130731_1800)中分别进行本地BLAST, 与同一蒺藜苜蓿PGIP基因具有最高得分和高度同一性的转化子被认为来自同一个PGIP基因。然后, 选取出现频率最高的片段在NCBI GeneBank(http://www.ncbi.nlm.nih.gov/)上进行BLASTn和BLASTp搜索。
将来自4对简并引物的PCR片段克隆入大肠杆菌后, 对转化子进行PCR鉴定和筛选, 最终有363个转化子被成功测序。对这些转化子, 首先在蒺藜苜蓿CDS和蛋白质数据库进行BLAST搜索, 结果有194个转化子与多个蒺藜苜蓿PGIP基因具有高度同一性, 且其所对应的苜蓿PGIP基因未被分离。经序列比对与聚类分析, 来自苜蓿PGIP基因的194个转化子被分成7类, 分别对应于7个不同的蒺藜苜蓿PGIP基因(表3), 因此, 可以认为这7类转化子分别来自7个不同的苜蓿PGIP基因。选择出现频率最高的序列在NCBI上进行BLAST搜索, 结果这些序列均与非苜蓿属植物的不同的PGIP基因具有最高得分和最高的核苷酸及氨基酸同一性(数据略), 进一步证实了上述推断。将新克隆的苜蓿PGIP基因分别命名为MsPGIP5、MsPGIP6、MsPGIP7、MsPGIP8、MsPGIP9、MsPGIP10和MsPGIP11, 每个PGIP基因选择一个代表性序列提交GeneBank, 且已被接受(表3)。然而, 与蒺藜苜蓿另外两个PGIP基因(Medtr7g033445.1和Medtr7g023740.1)相对应的苜蓿PGIP基因序列没有被克隆出来。
| 表3 本研究克隆的苜蓿PGIP基因序列 Table 3 Sequences of alfalfa PGIP genes |
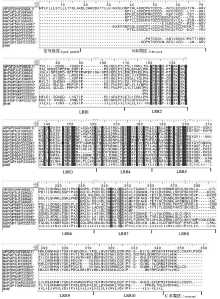
在本研究所克隆的7个苜蓿PGIP基因中, MsPGIP5、MsPGIP6、MsPGIP10和MsPGIP11均包含了它们各自基因的大部分编码序列(PGIP基因一般不包含内含子), 长度分别为801、861、858和813 bp, 均包含了部分C末端区、10个LRR保守基序和部分N末端区(表3和图1)。其他3个基因均只克隆出较短的序列, 其中, MsPGIP7序列包含了部分C末端区、前6个LRR保守基序和第7个LRR保守基序的部分序列; MsPGIP8和MsPGIP9仅包含第2个LRR保守基序的部分序列、第3―7个LRR保守基序和第8个LRR保守基序的部分序列。在先前发现的4个PGIP基因中, PGIP2和PGIP4 均在第5和第6个LRR保守基序处有部分缺失, 合起来相当于缺失了一个LRR保守基序, 但新克隆的7个PGIP基因均不存在这种变异。
 | 图1 已发现的苜蓿PGIP基因氨基酸序列的多序列对齐结果注:该结果由MEGA5的Muscle方法产生并经人工调整; 星号标记的序列为本研究所发现的序列; AtPGIP2 (AF229250)为已发现的拟南芥PGIP基因; LRR1-LRR10为10个富含亮氨酸的重复(LRR)保守基序。Fig.1 Results of multisequence alignment for amino acid sequences of alfalfa PGIP genesNote:The results is produced by the method of Muscle and adjusted manually; the starred sequences are found by the research; AtPGIP2 (AF229250) is the found PGIP gene of Arabidopsis thaliana; conserved motifs of LRR1 to LRR10 are leucine-rich repeats. |
由于在7个新克隆的苜蓿PGIP基因中, MsPGIP5、MsPGIP6、MsPGIP8、MsPGIP9和MsPGIP11有较多的转化子被测序, 因此, 可以对他们进行序列比对分析和候选SNP位点的统计(表3)。当低频率碱基的最低频率定为0.1时, 这5个基因分别各发现了39、6、12、1和38个候选SNP位点。其SNP位点间的平均距离分别为20、74、34、423和21 bp。
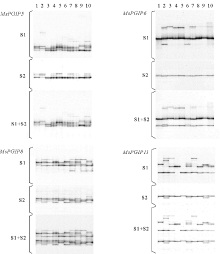
在7个苜蓿PGIP基因中, 可能是由于所设计的引物序列中包含有未检测到的变异位点, 导致MsPGIP7和MsPGIP10只有较少的转化子被测序; 而MsPGIP9仅有一个SNP被发现, 因此这3个基因没有做进一步的FSSCP分析。其他4个基因经过反复的PCR和电泳条件优化, 最终均得到了良好的SSCP电泳结果(图2)。其中, MsPGIP6和MsPGIP11的两条DNA单链所产生的两组带可被明显分开, 而MsPGIP5和MsPGIP8的两条DNA单链所产生的两组带均混杂在一起, 没有分开。对每一个基因, 均选用扩增条带较多的一条单链产生的FSSCP图谱进行等位基因的鉴定(图2中的S1), 迁移率不同的带被视为不同的SSCP等位基因, 结果MsPGIP5、MsPGIP6、MsPGIP8和MsPGIP11分别发现了16、5、9和13个等位基因。如果将SSCP等位基因当作SNP位点, 则其平均距离分别为20、56、22和19 bp(表4)。SSCP分析与序列分析的结果都表明, MsPGIP5和MsPGIP11的SNP频率高, MsPGIP8中等, MsPGIP6较小, 而MsPGIP9最低。
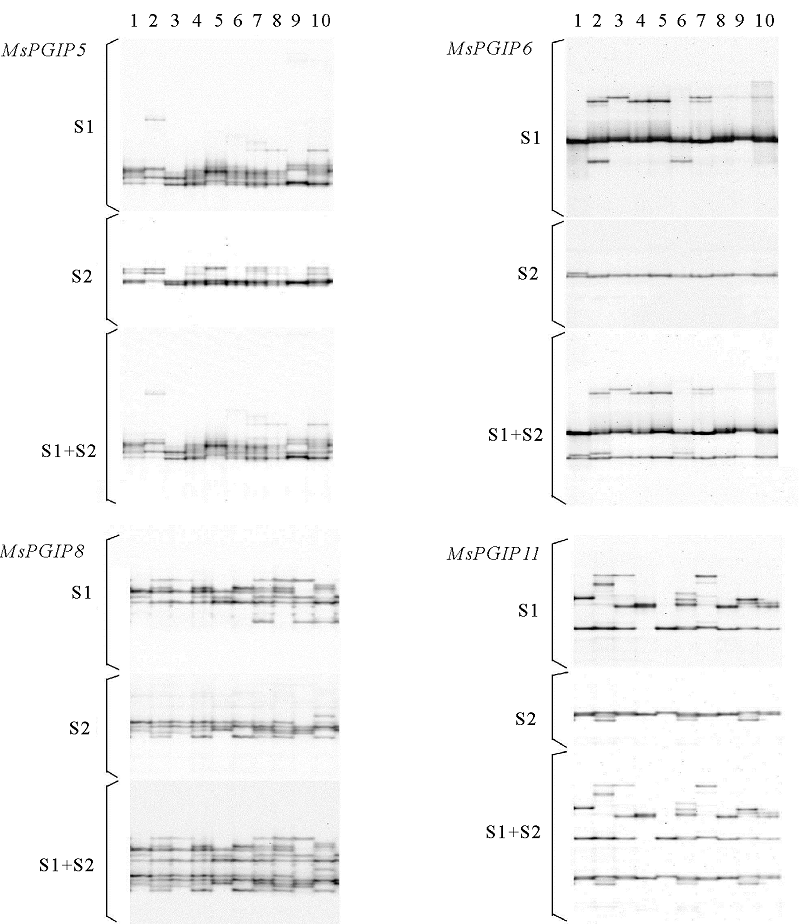 | 图2 4个苜蓿PGIP基因的FSSCP分析图谱注:泳道1~10为10个单株; S1和S2分别为两条DNA单链的SSCP电泳图; S1+S2为两个单链SSCP电泳图的重叠图。Fig.2 FSSCP analysis map of 4 alfalfa PGIP genesNote:The lanes of 1~10 are 10 individual plant’ s electrophoretogram; S1 and S2 are SSCP electrophoretograms of two ssDNAs; S1+S2 is the overlapping image of SSCP electrophoretograms of two ssDNAs. |
| 表4 4个PGIP基因的FSSCP引物及分析结果 Table 4 FSSCP primers and analysis results of 4 PGIP genes |
苜蓿为自交不亲和的同源四倍体植物, 其个体植株在基因型上是异质的。因此, 对本研究中的目标基因来说, 苜蓿集群DNA相当于不同等位基因的混合, 其中每个等位基因所占的比率相当于其等位基因频率。所以, 本研究中克隆测序的结果可用于分析其SNP变异。
Muller等[19]和Doris等[20]对苜蓿中一个在进化上呈中性的谷氨酸合成酶基因的研究表明, 其SNP位点间的平均距离为31 bp。本研究对分离到的5个PGIP基因(MsPGIP5、MsPGIP6、MsPGIP8、MsPGIP9和MsPGIP11)进行了SNP分析。结果发现, 他们的SNP的平均距离存在较大差异。比较而言, 本研究中MsPGIP9的 SNP位点间的平均距离为423 bp, 明显高于谷氨酸合成酶基因, 表明其在进化中受到了强烈的选择压力。而MsPGIP5和MsPGIP11的SNP位点间的平均距离明显低于谷氨酸合成酶基因(分别为20和21 bp), 表明其受到了较小的选择压力。MsPGIP8的SNP位点间的平均距离与谷氨酸合成酶基因接近, 其在进化上呈中性。
SSCP是一种简便、快速、灵敏的DNA突变检测方法, 其基本原理是通过电泳检测由单个核苷酸或其他小的核苷酸改变所引起的单链DNA分子的构象改变[21, 22]。SSCP已在多种生物中被证明是一种高效的研究遗传变异的方法, 也已在许多植物中得到了应用[23, 24, 25]。Gui等[15]的研究表明, 在多倍体物种中进行SSCP分析时, 采用向PCR产物中添加引物并结合荧光标记的方法, 才能得到较好的结果。
本研究采用这种方法, 对7个PGIP基因中的4个(MsPGIP5、MsPGIP6、MsPGIP8和MsPGIP11)进行了分析, 结果进一步证实了Gui等[15]的结论, 即:MsPGIP5和MsPGIP8的两条DNA单链所产生的两组带的迁移率均较接近, 采用银染法时将混杂在一起, 难以得到数据, 而采用荧光标记法时, 每组条带都可以得到一张电泳图谱, 很容易获得最终的数据; 而MsPGIP6和MsPGIP11的两条DNA单链所产生的两组带差异明显, 因此在今后的试验中, 这两个基因可以采用银染法进行分析以降低试验费用。在实际试验中, 由于对每条引物都采用合适的荧光素进行了标记, 所以4个基因被分成了两组(MsPGIP5/MsPGIP6和MsPGIP8/MsPGIP11), 分别在两块胶上进行电泳分离和图像扫描, 因此, 提高了试验的效率。
对4个基因的FSSCP结果进行分析后发现, 如果将SSCP等位基因当作SNP位点, 则其平均距离分别为20、56、22和19 bp, 与这4个基因的候选SNP位点间的平均距离基本一致(20、74、34和21 bp)。这个结果不仅表明FSSCP分析可检测到绝大部分的等位基因变异, 而且还表明MsPGIP5和MsPGIP11存在较大的核苷酸多态性, 这与SNP分析的结果是一致的。而MsPGIP6和MsPGIP8则分别检测到了相对较少和较多的SSCP等位基因, 这可能主要是由两方面原因造成的:第一, PCR扩增区域包含的SNP位点数与SNP统计区域差异较大; 第二, SSCP分析对序列组成不同的PCR扩增片段的分辨能力不同。
本研究使用同源克隆法成功分离了MsPGIP5、MsPGIP6、MsPGIP7、MsPGIP8、MsPGIP9、MsPGIP10和MsPGIP11共7个苜蓿PGIP基因的部分基因组编码序列, 并为其中4个基因建立了FSSCP分析方法。序列分析与SSCP分析结果表明, MsPGIP5和MsPGIP11存在较大的核苷酸多态性, MsPGIP8变异中等, MsPGIP6变异较小, 而MsPGIP9则高度保守。这为进一步进行关联分析等遗传学研究和cDNA全长克隆等分子生物学提供了良好的基础。
The authors have declared that no competing interests exist.
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|
| [19] |
|
| [20] |
|
| [21] |
|
| [22] |
|
| [23] |
|
| [24] |
|
| [25] |
|