

{kind=link}
{kind=link}
{kind=link}
{kind=link}
基于生长度日和降水量的韩国饲用玉米产量预测模型构建
[彭京伦1  , 王娟
, 王娟2 , 金抆主3 , 曹武焕4 , 金炳完1 , 成庆一1 ]
, 王娟]
|
|


第一作者:彭京伦(1989-),男,山东平邑人,研究员,博士,主要从事饲用作物和牧草产量预测模型和反刍动物营养研究。E-mail:pengjinglungood@163.com
本研究基于韩国不同地区的气象数据和饲用全株玉米( Zea mays)产量的历史记录数据,利用一般线性模型进行了饲用全株玉米的干物质产量预测模型的构建。作物产量等相关数据采集自韩国农业协同组合中央会饲料作物研究课题报告,气象数据采集自韩国国家气象厅网站。经过4个步骤的数据整理,最终用于模型构建的数据集包含了22年间(1988-2011年)的775个数据点。以干物质产量为因变量,通过逐步回归分析,两个气象变量被选定为构建产量预测模型的最适气象变量。进一步,通过一般线性模型,构建了包含两个选定的气象变量和以虚拟变量形式考虑进模型的栽培地域变量的韩国饲用全株玉米产量预测模型: DMY=11.298 SHAGDD-3.651 SHP+1 089.870 +Location。其中, DMY为饲用全株玉米的干物质产量, SHAGDD为播种到收获累积生长度日, SHP为播种到收获累积降水量。通过残差分析和10折交叉验证对所构建的模型进行了检验。根据此产量预测模型,可以发现作物生长期间的温度和降水量对饲用全株玉米的干物质产量有着显著的影响。因此,确定合理的播种和收获时间以使作物获得充分的生长对确保合理的作物产量有着重要意义。此外,基于韩国夏季降水相对集中的气象条件,选择拥有较好排水性的土地和较强耐涝性的作物品种,也是确保饲用全株玉米产量的重要因素。
The objective of this study was to construct a dry matter yield (DMY) prediction model for whole crop maize (WCM, Zea mays) on the basis of climatic data by location in South Korea. The forage crop and climatic data were collected from the reports of national research projects on forage crops and the website of Korea Meteorological Administration, respectively. The data set ( n=775) of 22 years(1988-2011) was used to construct the model after a four-step data preparation. Two optimal climatic variables were selected through stepwise multiple regression analysis, with DMY as the dependent variable. Subsequently, using a general linear model, the final model, whichincluded the two climatic variables and cultivated location (in the form of a dummy variable), was constructed as follows: DMY=11.298 SHAGDD-3.651 SHP+1 089.870 +Location, where SHAGDD refers to seeding-harvest accumulated growing degree days and SHP, seeding-harvest precipitation. The homoscedasticity and assumption that the mean of the residualsequal to zero was satisfied and the reliability of the model were good,since most scatters of the predicted DMY values fell within the 95% confidence interval. The model was tested using residual diagnostics and 10-fold cross-validation. The results showed that the variables related to temperature and precipitation had significant effects on the WCM yield. Therefore, accurate determination of sowing and harvest dates is important to ensure that the crops grow under appropriate accumulative temperature conditions. Furthermore, land with good drainage and cultivars with strong tolerance to water logging are necessary for the cultivation of WCM in South Korea because of excessive precipitation during the growing season.
随着现代农业的发展, 作物产量预测模型研究成为科学实施农业生产的重要手段[1, 2]。在韩国, 围绕作物产量预测模型的研究主要集中在粮食和经济作物上[3, 4]。随着韩国经济社会的发展, 其对畜牧产品的需求不断增大, 但在促进畜牧业发展至关重要的饲料作物和牧草的产量预测研究上却显不足。通过对饲料作物和牧草产量预测模型的研究, 将为指导韩国饲草产业的发展和促进韩国畜牧业的发展提供一定的理论参考。
饲用全株玉米(Zea mays)是韩国重要的饲料作物[5], 具有较高的能量和较好的适口性, 是重要的反刍动物粗饲料资源和精饲料原料, 深受韩国畜牧业者喜爱, 栽培面积从2007年的6 400 hm2增长到2014年的10 800 hm2[6]`。因此, 本研究选取了饲用全株玉米作为研究对象来进行其产量预测模型构建的研究。
作物产量预测的方法主要有3种:作物仿真模型、遥感预测模型和统计模型。作物仿真模型需要大量参数, 开发需要大量投入; 遥感测产主要应用于大面积连片作物[7]。受限于耕地面积较小, 韩国的饲料作物栽培规模并不大且呈现地理上散布的状态[8]。与此同时, 与饲料作物生产相关的生理生育特性的数据积累也并不充分。因此, 以上这两种作物产量预测方法并不是十分适合于韩国的饲料作物产量预测。
目前, 韩国气象数据的观测和积累状态较好, 相关数据可以较方便地获得并且质量也较好。利用包含气象变量的统计模型进行作物产量预测研究应用非常广泛, 而且投入少, 需要的变量也少, 便于使用和维护[7]。因此, 本研究中选用统计模型的方法来构建基于气象数据的韩国饲用全株玉米产量预测模型。一般而言, 气象-作物产量预测统计模型是基于长期的作物产量历史记录和几个选定的气象变量如气温和降水等而构建的[7]。气象-作物统计模型的优点在于模型的构建相对简单, 对数据量的需求相对不大而且投入一般相对不大。因此, 有许多研究项目采用了回归分析方法来预测作物产量和分析环境变量对作物生育的影响[9, 10, 11, 12, 13, 14, 15]。
玉米作为一种暖季型作物, 播种到收获之间适当的累积生长度日、日照时长和降水量是保证玉米产量的重要因素[16, 17]。因此, 本研究的目的是:1)基于相关气象变量, 通过一般线性模型构建用于饲用全株玉米产量预测的气象-作物统计模型; 2)通过残差检验10折交叉检验对模型进行检验。
本研究中所用的饲用全株玉米数据收集自韩国农业协同组合中央会从1988年到2011年的22年间(1992年和1997年无记录)主持进行的牧草和饲料作物新品种引进适应性试验报告。采集的原始数据的样本容量为1 027, 进而, 由于数据重复或低信赖性, 34个数据点被删除。
基础气象数据采集自韩国气象厅网站, 根据数据集中试验年度和栽培地位置收集了对应气象站的日最低气温、日最高气温、日平均气温、日照时长和日降水量等逐日基础气象数据。进而, 结合作物栽培过程的播种、出丝、收获等时间信息, 生成了播种期到出丝期累积生长度日(SSAGDD, seeding-silking accumulated growing degree days, ℃· d)、播种期到收获期累积生长度日(SHAGDD, seeding-harvest accumulated growing degree days, ℃· d)以及播种期到收获期平均温度(SHMT, seeding-harvest mean temperature, ℃)3个气温相关变量, 播种期到收获期降水量(SHP, seeding-harvest precipitation, mm)和播种期到收获期降水日数(SHDP, seeding-harvest number of days with precipitation, d)2个降水量相关变量以及播种期到收获期累积日照时间(SHDS, seeding-harvest duration of sunshine, h)1个日照相关气象变量用于分析建模。SSAGDD为从播种日开始到出丝为止每日生长度日的总和, SHAGDD为从播种日到收获日的每日生长度日的总和。生长度日是分析作物完成某一生长发育阶段所经历的累计有效积温值[5], 每日生长度日的计算方法:
GDD=[(Tmax+Tmin)/2]-10。 (1)
式中:当日最高温度Tmax 超过30 ℃时, 取30 ℃; 当日最低温度Tmin低于10 ℃时, 取10 ℃。SHMT为播种日到收获日每日平均气温的平均值。SHP为播种日到收获日为止每日降水量的总和。SHDP为播种日到收获日降水日数的总和。SHDS为播种日到收获日每日日照时数的总和。
最终, 将作物产量数据集和生成的气象变量数据集合并后形成了统计分析用数据集。其中, 217个因没有记录播种、吐丝或者收获日期, 无法计算对应的气象变量的数据点和1个通过统计方法检测并结合专家意见被判定为异常值的数据点被删除, 进而生成了包含775个数据点的最终数据集, 每个数据点包含作物干物质产量(dry matter yield, DMY)、栽培地域和6个气象变量等项目。最终数据集包含的9个栽培地域的位置及其样本容量为:Gimje(样本容量:4), Sangju(样本容量:26), Seongju(样本容量:152), Seonghwan(样本容量:271), Suwon(样本容量:178), Yeongju(样本容量:4), Icheon(样本容量:64), Jeju(样本容量:11)和Jinju(样本容量:65)。
1.2.1 变量的描述性统计分析与建模用最适变量的筛选 本研究通过描述性统计方法分析了所有变量的平均值、中值、第一百分位数和第三百分位数用以进行变量分布的判别。同时, 由于本研究中包含多个描述相似项目的自变量, 如累积降水量与累积降水日数等, 这些变量之间有着密切的数量关系和较强的相互关联性, 它们之间存在多重共线性的可能性很高。多重共线性是当多元回归分析中两个或多个自变量之间相关性强时所呈现出的问题, 并会导致逆矩阵不可求进而造成回归系数的扭曲[18]。本研究中通过计算各自变量间的方差膨胀因子(VIF, variance inflation factors)对变量间多重共线性的存在进行了初步检验。为了进一步确定哪些变量之间存在着显著的共线关系, 本研究构建了所有变量间的皮尔逊相关系数矩阵。一般而言, 当自变量间的皮尔逊相关系数的绝对值超过0.7且相关关系显著时可断定两变量在回归分析中存在多重共线性的可能性较大[18]。基于变量间的多重共线性和相关关系, 一部分适宜于模型构建的变量被选择出来。
为了进一步挑选构建模型用的最适气象变量, 本研究利用逐步回归分析方法对初步筛选后的变量进行了分析。在逐步回归分析方法中, 自变量将依据其对因变量作用的显著程度, 依大小逐个被引入回归模型[19]。由于在引入新变量的同时, 已经被引入模型的自变量对因变量影响的显著程度可能发生变化, 模型中已经引入的自变量与因变量之间相关的显著性将被重新检测, 不显著的自变量将被剔除出回归模型。此过程反复进行直到模型中包含的自变量均对因变量作用显著而未被引入模型的变量均对因变量无显著作用。
1.2.2 基于一般线性模型构建最终产量预测模型 最终产量预测模型的构建利用了包含连续型自变量(气象变量)和虚拟变量(栽培地域)的一般线性模型。一般线性模型的公式:
Yn× 1=Xn× (p+1)β (p+1)× 1+Zn× cγ c× 1+ε n× 1, ε ~ i.i.d.N (0, δ 2)(2)
式中:Y为因变量向量, 在本研究中为DMY; X为连续性自变量向量, 在本研究中为经之前步骤所选定的气象变量; β 项为自变量回归系数矩阵; Z项为虚拟变量(c=4)矩阵; γ 项为虚拟变量的回归系数矩阵; ε 项为残差向量, ε 需满足独立同分布假设(均值为0方差为δ 2)。虚拟变量用于将栽培地域这一定性变量转化为以0和1表示的定量变量。在本研究中, 栽培地域的数目为9, 因此本研究中虚拟变量包含4个值来表示9个地域变量。例如, Gimje和Sangju用虚拟变量表示的形式为(1, 0, 0, 0)和(0, 1, 0, 0)。此外, 表示最后一个栽培地域变量Jinju的虚拟变量形式为(0, 0, 0, 0)。最终模型的构建, 仅考虑了经过之前步骤之后所选定的气象变量和栽培地域变量的主效应, 变量之间的交互效应未引入模型。
1.2.3 模型评价 本研究中生成了饲用全株玉米产量预测模型残差的正态Q-Q图(Q-Q plot, the normal quantile-quantile plot) 以检验该模型的残差是否满足正态分布假设。Q-Q图的横轴和纵轴分别表示模型标准化残差分位数(Quantiles of the Standardized Residuals)和正态分布理论分位数(Normal Theoretical Quantiles)。在Q-Q图中, 若所有的点都密切地分布在45° 线上或附近, 则说明残差服从均值为0的正态分布[19, 20]。此外, 通过绘制模型的标准化残差对应预测值的散点图可对残差分布的随机性进行检验, 若散点均匀地分布在纵轴0刻度线的两侧且无特定几何规律, 可判断所构建的模型满足方差齐性和独立性假设[19, 20]。此外, 本研究中还生成了用于比较数据中的干物质产量观测值和经过模型计算获得的干物质产量预测值的95%置信区间图。在预测值的95%置信区间图中, 若图中的点大部分散布在95%置信区间内, 则可推断本研究所构建的模型用于预测的信赖度较好[20]。
1.2.4 模型精度检验 本研究中应用10折交叉验证对模型的精度进行了评估。首先随机将数据集分成10个子集, 每次将9个子集作为训练数据集, 剩余的1个子集用作测试数据集。然后, 依据本研究中构建的产量预测模型所包含的变量利用训练数据集的数据建立新的模型, 并且基于训练数据集中的自变量计算干物质产量的预测值。然后用建立的模型计算测试数据集的干物质产量预测值。之后, 建立训练数据集和测试数据集各自的预测值和观测值的回归散点图并计算各自的调整决定系数(Adjusted R-squared)和标准均方根误差(NRMSE, normalized root-mean-square error)。以上过程重复进行10次, 直到所有的数据子集都用作1次测试数据集为止。然后计算训练数据集和测试数据集所有10次回归决定系数的平均值(R2 fit和R2 val)和标准均方根误差的平均值(NRMSE val和NRMSE fit)以衡量模型的精度。NRMSE的计算公式如下:
RMSE=
NRMSE=RMSE
式中:PREi表示第i个产量预测值, OBSi表示第i个产量观测值, OBS表示观测值的平均值, n表示数据集的样本容量。
NRMSE可以用来评价模型对数据的拟合优度。一般而言, 当NRMSE< 10%时, 模型的拟合优度好; 当10%≤ NRMSE< 20%时, 模型的拟合优度较好; 当20%≤ NRMSE< 30%时, 模型的拟合优度一般; 当NRMSE> 30%时, 模型的拟合优度较差[21, 22, 23]。若所构建的模型在交叉验证中对训练数据集和测试数据集的拟合优度都较好则说明模型的精度较好。
本研究中使用Microsoft Excel 2010 软件对数据进行了整理, 进而通过SPSS 22.0软件进行了统计分析。
数据集中饲用全株玉米干物质产量的平均值和中值分别为16 056.32和15 756.00 kg· hm-2(表1)。第一和第三百分位数分别为13 483.00和18 622.00 kg· hm-2。平均值和中值近似, 同时均值与第一百分位数之差近似于第三百分位数与均值之差(2 573.32和2 565.69)。由此可以判断, 数据集中的干物质产量的分布基本满足正态性要求, 可以用作回归分析的因变量。此外, 根据自变量的方差膨胀因子均小于3可以推断自变量间无十分显著的多重共线性[19, 20]。
| 表1 饲用全株玉米数据集中各变量的描述性统计量和方差膨胀因子 Table 1 Descriptive statistics and variance inflation factors for all the variables in the datasetforwhole crop maize |
根据饲用全株玉米数据集中各变量的相关系数(表2)可以发现, SHMT和SHDP与DMY之间无显著的相关关系, 因此剔除了这两个自变量。剩余的4项自变量SSAGDD、SHAGDD、SHP和SHDS将被用于回归分析中。
| 表2 饲用全株玉米数据集中变量的相关系数矩阵 Table 2 Correlation matrix that includes all the variables in the dataset forwhole crop maize |
通过逐步回归分析, 在显著性标准设定为0.05时, 从SSAGDD、SHAGDD、SHP和SHDS这4个变量中选取了最适气象变量SHAGDD和SHP(表3), 所得的回归模型的调节决定系数为20.9%(P< 0.01)。在此模型中, 依据所有自变量(SHAGDD和SHP)的方差膨胀因子均小于2, 以及其各自的皮尔逊相关系数、偏相关系数和部分相关系数之间符号相同大小相近, 可以确定选定的自变量间的多重共线性问题的排除[24]。此外, 由变量SHAGDD的相关系数的绝对值大于SHP的相关系数的绝对值可以判断, 饲用全株玉米从播种到收获的生育时间段内, 温度和降水量对作物的干物质产量影响显著, 且温度对干物质产量的影响更强。
| 表3 利用逐步回归分析选择统计最适气象变量的结果 Table 3 Results for the selection of statistically optimal climatic variables via stepwise multiple regression for the prediction model of whole crop maize (adjusted R2=0.209* * ) |
为了进一步改善模型的拟合优度, 在无法获取更多作物栽培数据(如作物栽培年度的土壤数据、管理方法数据和品种数据等)的情况下, 本研究中将栽培地域这一变量以虚拟变量的形式考虑进模型。利用一般线性模型构建了包含连续型自变量(SHAGDD和SHP)和虚拟变量(栽培地域)的韩国饲用全株玉米干物质产量预测模型(表4), 模型的调整决定系数升高到了30.5%(P< 0.01)。模型的表达式如下:
DMY=11.298SHAGDD-3.651SHP+1 089.870+Location 。(5)
对于某一个栽培地域, 模型公式中的Location项将由表4中所对应的常数项替代。此外, 基于变量的偏埃塔平方, 可以判断与未添加栽培地域变量前一样, SHAGDD对饲用玉米干物质产量的影响要大于SHP(表4)。
| 表4 利用一般线性模型构建韩国饲用全株玉米产量预测模型结果 Table 4 Results for the general linear model for whole crop maize yield prediction with selected climatic variables and cultivated locations (adjusted R2=0.305* * ) |
在韩国, 降水主要集中在夏季也是玉米的主要生育期内。本研究所用的数据集中, 超过70%的数据点所对应的SHP均超过了600 mm(图1)。一般而言, 在温带区域, 玉米在生育期间的最适累积降水量为450~600 mm[25], 过多或过少的降水量都可能对作物的生育带来不利影响进而影响作物干物质产量。这也就意味着在韩国由于夏季过多的降水, SHP这一变量对饲用全株玉米干物质产量将会产生抑制作用, 因此在模型中, SHP的回归系数表现为负值。
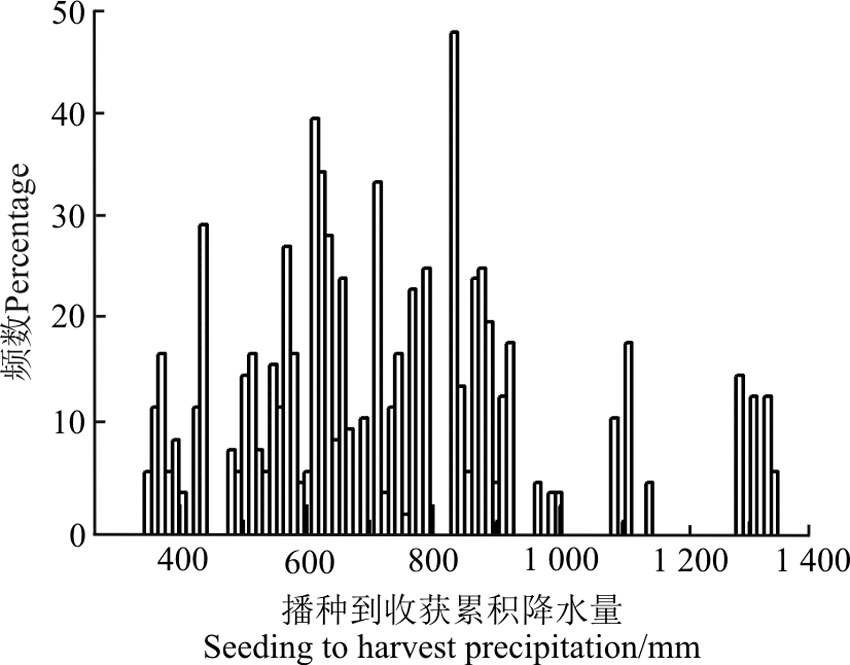 | 图1 播种期到收获期累积降水量(SHP)的分布图Fig. 1 Distribution of seeding-harvest precipitation (SHP) in the final dataset forwhole crop maize |
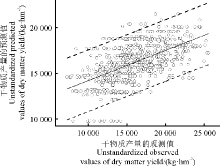
饲用全株玉米产量预测模型的残差正态Q-Q图中(图2a), 点都密切地分布在45° 线附近, 说明本研究中构建的模型的残差服从均值为0的正态分布。在标准化残差对应预测值的散点图中(图2b), 点均匀地分布在纵轴0刻度线的两侧且无特定几何规律可判断本研究中所构建模型的残差满足方差齐性和独立性假设。此外, 在预测值的95%置信区间图中(图3), 点大部分散布在95%置信区间内, 可以推断所构建的模型用于预测的信赖度较高。
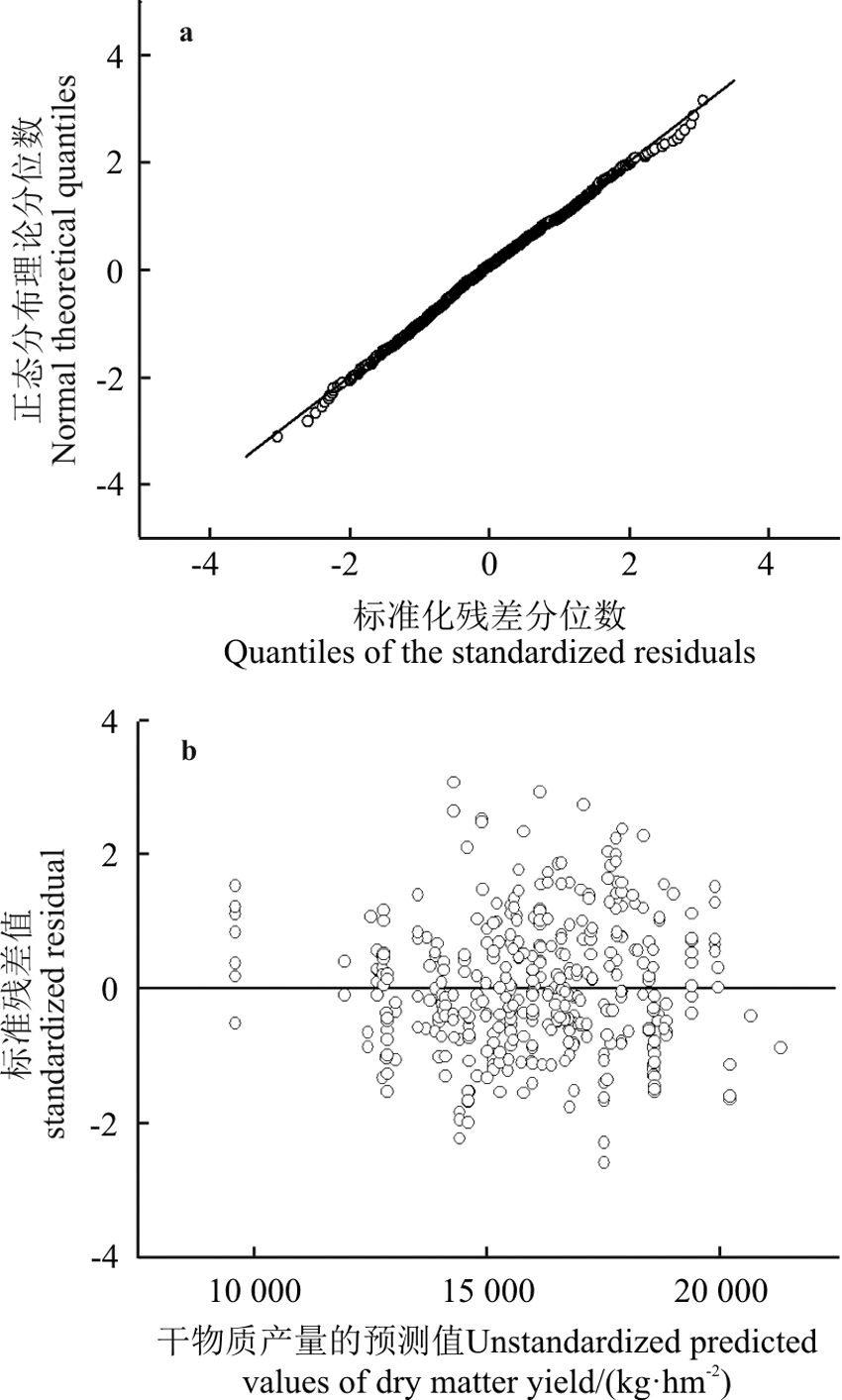 | 图2 饲用全株玉米产量预测模型的残差诊断结果a, 残差的正态Q-Q图; b, 标准化残差对应预测值的散点图。Fig. 2 Results of the residual diagnostics for the model ofyield predictionfor whole crop maizea, normal Q-Q plot of regression standardized residual; b, scatter plot of standardized residuals against predicted values of dry matter yield from the model. |
 | 图3 饲用全株玉米产量预测模型的预测值的95%置信区间图Fig. 3 Scatter plot of observed and predicted dry matter yield with the yield prediction modelof whole crop maize, including mean regression line and 95% confidence interval |
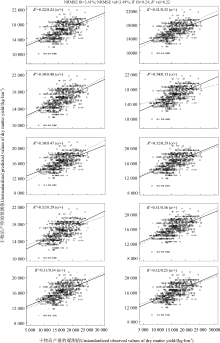
从10折交叉验证过程中每次验证后所得训练用数据集和测试用数据集中预测值和观测值之间的回归散点图(图4)可以看出, 十次交叉验证的训练数据集中预测值和观测值回归分析决定系数的平均值(R2 fit)和标准均方根误差的平均值(NRMSE fit)分别为0.24和3.41%。同时, 十次交叉验证的测试数据集中预测值和观测值回归分析决定系数的平均值(R2 val)和标准均方根误差的平均值(NRMSE val)分别为0.22和3.49%。由此可以推断, 本研究所构建的模型的精度较好。
 | 图4 饲用全株玉米产量预测模型的10折交叉验证结果o 表示训练用数据集, + 表示验证用数据集。Fig. 4 Results of the 10-fold cross-validation for the whole crop maize yield prediction model, |
showing fit of predicted yield values for both training and test sets in relation to the observed yield values
The symbol “ o” represents the training set, while “ +” represents the test set.
一般而言, 影响作物生育的生态因素可以被划分为5类:气象因素、土壤因素、生物因素、地形因素和人为因素[26, 27, 28]。在其他数据记录和积累情况并不理想的情况下, 本研究中仅利用气象资料作为解释变量, 通过统计方法建立了气象-作物产量预测模型。作物当前的生育状况是由过去的气象条件等因素所影响的。同时, 未来的气象条件将会决定作物的潜在生产性能。一定地域的气象状况以年为单位重复变化。与此同时, 每天的气象数据在连续的时间维度上可以看作为一个连续的正态概率分布。具有这样特点的气象变量可以被数量化, 进而通过量化的历史气象变量记录资料来预测作物潜在产量是可行的。
经过变量筛选, 最终选定的用于构建产量预测模型的变量为播种期到收获期累积生长度日和播种期到收获期累积降水量。可见, 在众多气象变量中, 温度和水分对于饲用玉米干物质的形成具有最显著的影响作用, 在韩国的饲用全株玉米的栽培中, 合理确定播种和收获时间以保证作物获得充足的光温条件对作物产量的保证有着重要意义。而且, 在仅包含气象变量的逐步回归模型和最终包含栽培地域的一般线性模型中, 温度对玉米产量的影响效果都大于降水的效果, 可见两个变量与玉米产量间影响程度的大小并不受栽培地域变化的影响。此外, 模型中降水变量负的回归系数以及数据集中降水变量的分布状况意味着在韩国夏季过多的降水对饲用玉米产量的形成产生了不利影响。因此, 在生产管理中, 选取土壤排水等级较好的田地, 注意田块的排水管理, 以及开发耐涝性好的品种, 对于韩国饲用玉米栽培管理有着较重要的意义。基于残差分析可以判断本研究中构建的模型对于数据的拟合度较好, 从十次交叉验证的结果来看, 模型的精度较好。但是, 本研究中所构建的模型的决定系数不高。非人工栽培的牧草在野外生态条件下的产量取决于土壤和气候状况, 而对于人工栽培的作物的产量, 管理因素则成为了产量波动的决定因素, 如品种、施肥时机和施肥量、杂草处理、灌溉时机和灌溉量等因素[29, 30, 31, 32, 33]。因此, 仅利用气候数据构建的人工栽培的作物产量预测模型的决定系数不高是合理的。进一步地收集土壤数据、品种数据、地形数据和管理数据, 并基于完善的数据构建新的作物产量预测模型来提高模型的调整决定系数是可行和必要的。由于该模型包含栽培地域, 因此在模型包含的相关地域使用该模型较为适宜。在后续研究中, 土壤、品种、地形和管理数据的添加, 将会消除原模型中栽培地域所代表的相关信息, 也因此, 新的模型将会不受栽培地域的限制而具有更广范围的使用适宜性。
本研究中通过一般线性模型建立了饲用全株玉米的产量预测模型, 模型的残差检验结果和交叉验证结果均较好。从研究结果可以判定, 温度和降水量对韩国饲用全株玉米的产量有着显著影响, 合理确定播种和收获日期, 选择耐涝性较好的品种和增强土壤的排水能力应当引起作物栽培者的重视。在进一步的研究中, 将通过追加环境因子变量和探究解释变量进入模型的形式的变化来进一步提高模型的拟合优度。
(责任编辑 武艳培)
The authors have declared that no competing interests exist.
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|
| [19] |
|
| [20] |
|
| [21] |
|
| [22] |
|
| [23] |
|
| [24] |
|
| [25] |
|
| [26] |
|
| [27] |
|
| [28] |
|
| [29] |
|
| [30] |
|
| [31] |
|
| [32] |
|
| [33] |
|